

The Evaluation Platform for AI Agents
Run public benchmarks, build private evaluation suites, and integrate regression testing into your CI/CD pipeline -- all on infrastructure purpose-built for agent execution.
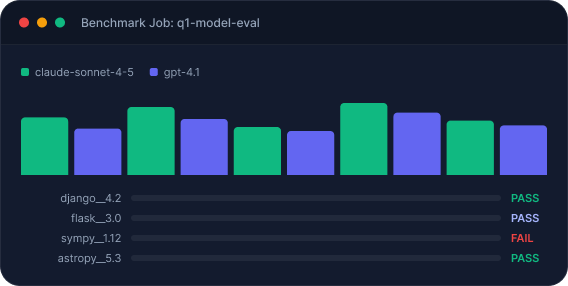
Evaluation is not just accuracy
Leaderboard rankings tell you which model scores highest on a generic task set. Production decisions require measurement across four dimensions.




Execution meets observability
Runloop runs your agent benchmarks. Weights & Biases tracks every metric, artifact, and experiment across runs. Together: a single workflow from benchmark execution to model selection.

Built with the evaluation community
Runloop partners with industry, non-profit, and academic organizations working to define evaluation standards for AI agents.
Two ways to run benchmarks
Every evaluation workflow runs through one of two modes. Choose based on your feedback loop speed and scale requirements.
Interactive Benchmark Runs
Real-time execution with streaming results. Submit a benchmark, watch scenarios complete, and consume structured output as it arrives.
Orchestrated Benchmark Runs
Declarative job submission with Harbor-compatible configuration. The platform handles provisioning, distribution, retry, and aggregation at scale.
Three tiers of evaluation scenarios
From industry-standard suites to your own proprietary codebase.
Run industry-standard evaluations on demand
Access established benchmarks like SWE-Bench Verified directly through the platform. Results are private to your organization, not submitted to a public leaderboard.

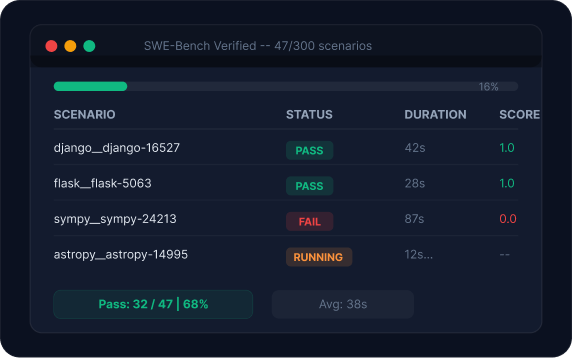
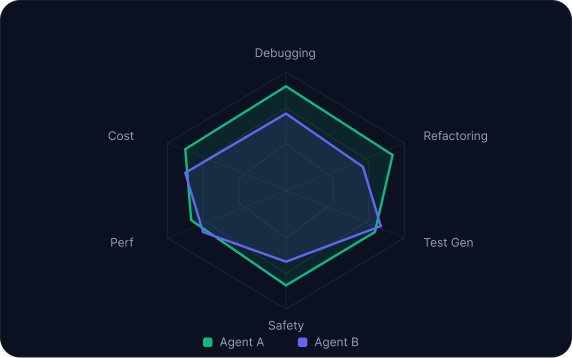
Isolate and measure specific capabilities
Curated benchmarks are themed scenario collections developed with academic researchers. Run 40 targeted scenarios instead of 300 broad ones.
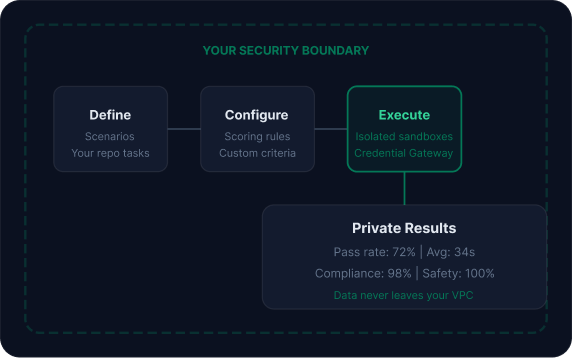
Build private benchmark suites on your own code
Custom benchmarks use your own repositories, task definitions, and scoring criteria. Credentials managed through the Credential Gateway.
What teams build on the platform
The two operational modes and three benchmark tiers combine to support these evaluation workflows.

Side-by-side model comparison
Hold one variable constant, change another, and compare results. The comparison dashboard surfaces where configurations diverge on per-scenario behavior.
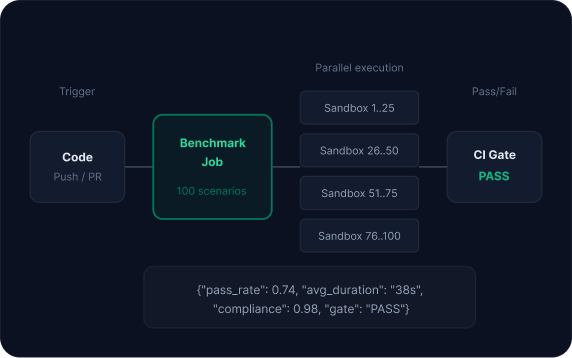
Regression testing in CI/CD
Define a baseline, then run it automatically when variables change: model updates, framework upgrades, prompt modifications. Results serve as CI/CD gates.
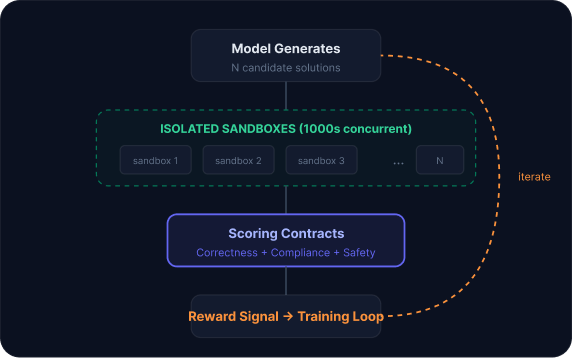
Training data generation for RFT and SFT
Fine-tuning workloads use Runloop's sandbox infrastructure as the execution substrate for training loops. Scoring contracts encode correctness, compliance, safety, and business logic into the reward signal.
Declarative benchmark job execution at scale
Submit a job specification. The platform handles everything between submission and structured results.




One API for every evaluation workflow
The same Benchmark Jobs API powers model evaluation, regression testing, and training data generation.
import runloop
# Submit a benchmark job -- same API for all evaluation workflows
job = runloop.benchmark_jobs.create(
name="q1-model-evaluation",
benchmark_job_def="agent-v3-full-suite",
variants=[
{"model": "claude-sonnet-4-5", "agent": "code-agent-v3"},
{"model": "gpt-4.1", "agent": "code-agent-v3"},
],
config={"concurrency": 100, "timeout_seconds": 300}
)
# Stream results as scenarios complete
for result in runloop.benchmark_jobs.stream_results(job.id):
print(f"{result.scenario}: {result.status}")
import Runloop from 'runloop';
const job = await runloop.benchmarkJobs.create({
name: 'q1-model-evaluation',
benchmarkJobDef: 'agent-v3-full-suite',
variants: [
{ model: 'claude-sonnet-4-5', agent: 'code-agent-v3' },
{ model: 'gpt-4.1', agent: 'code-agent-v3' },
],
config: { concurrency: 100, timeoutSeconds: 300 }
});
for await (const result of runloop.benchmarkJobs.streamResults(job.id)) {
console.log(`${result.scenario}: ${result.status}`);
}
# Submit a benchmark job
runloop benchmark create \
--name "q1-model-evaluation" \
--def "agent-v3-full-suite" \
--variant "model=claude-sonnet-4-5,agent=code-agent-v3" \
--variant "model=gpt-4.1,agent=code-agent-v3" \
--concurrency 100
# Stream results
runloop benchmark stream <job-id>
From model selection to production monitoring
One evaluation platform for performance, cost, compliance, and safety -- across public benchmarks, private suites, and CI/CD integration.
Need enterprise deployment? Talk to Sales






