We use cookies to provide you with the best possible experience. They also allow us to analyze user behavior in order to constantly improve the website for you. Privacy Policy and Terms of Service
Model Context Protocol (MCP) - Understanding the Game-Changer
MCP lets LLMs plug into real tools and data. With support from GitHub, Slack, Cloudflare, and Sentry, it makes AI way more useful in real work.
LLMs took a huge step out of the chat window and into the broader digital world with the release of Model Context Protocol (MCP) by Anthropic in November 2024. Sometimes described by Anthropic as a “protocol for seamless integration between LLM applications and external data sources,” MCP has already been adopted by crucial data stores from GitHub to Slack, as well as enterprise platforms like Cloudflare and Sentry.
MCP is a method for systematically organizing the data, instructions, and domain knowledge an LLM needs to generate consistent outputs. Instead of mapping a model’s response to a predefined function signature, MCP centers on creating layers of context—such as user intent, historical conversation context, brand guidelines, or task-specific instructions. This layering structure lets developers prioritize different aspects of the conversation and incorporate updates without rewriting core application logic.
Key MCP Mechanics and Structure
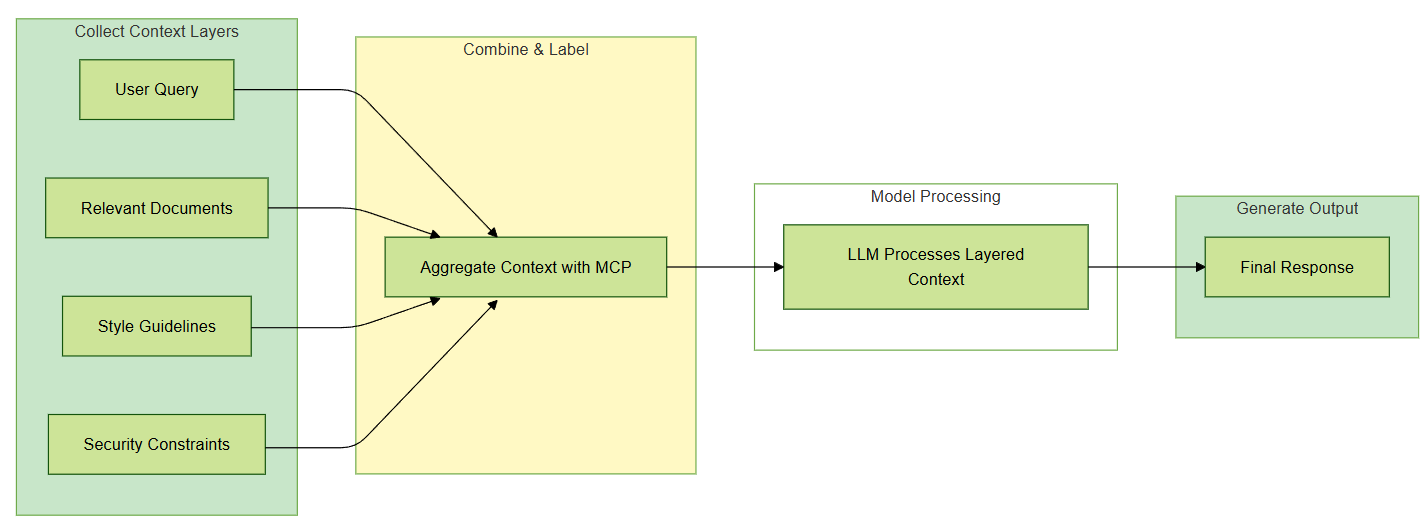
MCP works by segmenting and labeling context blocks: user queries, relevant documents, style guidelines, or security constraints. Each layer is processed by the model according to the instructions tied to that layer. This reduces reliance on one large prompt and provides a maintainable workflow for complex applications.
For example, a customer support chatbot might pull account information from GitHub version history (for code-based questions) and company policy details from a separate data store. The model then consults these layers in sequence—first referencing user-provided details, then policy documents—before formulating its answer.
Below is a flowchart illustrating how MCP’s layering process works. Each labeled block represents a distinct context layer, showing how user queries, policy documents, and style guidelines feed into the final output. In a local or server-side implementation, you might gather these blocks from various data stores or a retrieval pipeline, then pass them to the LLM. The layered instructions guide how the model interprets the question and formulates its final response.
Comparison to Other Context-Injection Methods
Many teams handle external data with approaches like Retrieval-Augmented Generation (RAG), embeddings, or large prompt concatenations. While MCP overlaps with these solutions in its ability to supply fresh context to a model, it has distinct benefits:
Structured Context Layers vs. Retrieved Snippets In a typical RAG workflow, the system searches an external database or vector store to retrieve relevant text snippets, which are then appended to the prompt. MCP, on the other hand, organizes context into labeled, modular “blocks” (e.g., brand guidelines, compliance policies, user queries) that can be updated or swapped independently. This means that RAG methods and MCP are not mutually exclusive. You could use RAG to find relevant text from a large knowledge base, then place those results in an MCP layer labeled “Retrieved Documents.” The layering system still applies, ensuring that brand policies, style guides, and the newly retrieved documents each have their own well-defined space.
No Replacement, but an Enhancement MCP is not intended to replace RAG, particularly when you need to access large dynamic corpora or real-time data. RAG remains an excellent approach for searching and embedding extensive information. MCP simply adds a higher-level framework around how that information is injected. Rather than dumping retrieved text into one massive prompt, developers can structure that text in a dedicated block that fits seamlessly (or “smoothly,” if you prefer to avoid “seamlessly”) alongside other context blocks. This modular structure improves maintenance and clarity. If a policy block requires updates, it can be revised without re-embedding or retraining. Meanwhile, RAG continues to handle queries that need data from outside sources. The two methods work well in tandem, allowing teams to combine advanced retrieval strategies with explicit layering for organization and context prioritization.
Previous Methods
Traditional approaches to managing LLM behavior often relied on monolithic prompts or fine-tuning. Monolithic prompts involve crafting a single, large prompt that includes all necessary instructions, context, and rules. While this can work for simple tasks, it becomes unwieldy for complex applications. For example, a customer support chatbot using monolithic prompts might need to include the entire company policy, brand guidelines, and user history in one massive prompt. This not only increases token usage (and cost) but also makes updates cumbersome—any change to policies or guidelines requires rewriting the entire prompt.
Fine-tuning, on the other hand, involves retraining the model on new data to adapt it to specific tasks or rules. While effective, this approach is resource-intensive and time-consuming. For instance, if an e-commerce platform updates its return policy, fine-tuning would require retraining the model on the new policy data, which can take days or weeks and risks degrading the model’s performance on other tasks.
MCP Advantages and Real-World Use
MCP excels where multi-turn conversation history and varied domain-specific instructions must be preserved. An internal IT help desk assistant could rely on MCP to handle employee questions about device policies and compliance training, ensuring each step of the conversation factors in the correct layer.
This approach also simplifies maintenance: updating a single context layer with new rules or product information rolls out across multiple applications without requiring changes to the core model or retraining. For instance, if a brand voice guide changes, only that layer is updated, automatically influencing responses across help desks, chatbots, and more.
Scalability Across Complex Interactions
Multi-turn conversations appear in customer service chatbots, internal help desk applications, and interactive dashboards. For example, a healthcare chatbot answering patient questions about medication side effects can pull previous conversation details about dosage and personal health conditions while adhering to rules encoded in MCP layers (e.g., HIPAA compliance).
Simplified Maintenance and Updates
MCP allows developers to isolate and update distinct blocks of context. If an e-commerce platform revises its return policies, only the relevant policy layer requires editing, and every connected chatbot or user interface automatically incorporates the change. This compartmentalization helps large enterprises maintain consistent, up-to-date responses across diverse user segments—from VIP customers to first-time shoppers.
So What Makes MCP a Gamechanger?
MCP introduces a clean, modular way to handle evolving context and domain-specific rules, addressing many friction points in traditional LLM deployments. Instead of crafting a single monolithic prompt or rewriting the model for each new policy, brand voice, or user question, developers can update individual “layers” of context and recompose them dynamically. This not only streamlines maintenance but also delivers more consistent, higher-quality output for multi-turn conversations where regulations, style guidelines, or user preferences shift from one turn to the next.
Key Advantages
Modular Updates: When a policy changes or a new product line is introduced, only a specific context block requires editing.
Scalable for Long Dialogs: Each turn in a conversation can inherit previous context, allowing the model to respond with continuity and precision.
Consistent Domain Enforcement: Different context layers—such as regulatory compliance or brand voice—are locked in by design, helping ensure they’re applied uniformly.
Reduced Training Overhead: Because the underlying model doesn’t need retraining for every new requirement, MCP supports faster iteration with minimal risk.
By adopting MCP, organizations can create a more maintainable, context-aware system for LLM applications—where each specialized instruction or regulation has its own clearly defined place. The result is a more dynamic and reliable approach to building AI-powered tools that keep pace with evolving policies, domains, and user needs.
Experience one of our demos that leverages the power of MCP on the Runloop.ai platform or explore our other articles on AI.


.webp)